大语言模型(LLM)与智能体(Agent)
2025 年的当下,大语言模型(LLM)已经是足够普及、无需赘述的概念。相比传统算法甚至深度学习类算法,LLM 展现出惊人强大的、处理泛化任务的能力。以往我们训练和调整模型,应用算法,是一个复杂而漫长的过程。而 LLM 让“应用算法”这件事,变得前所未有的简单。大模型内部预训练固化的能力足够全面而强大,通过自然语言描述就可以激活对应的专业能力解决问题。我们不再需要改进模型本身,这件事可用交由基础大模型厂商通过天量数据、精妙算法、巨额投资和绝顶人才去完成。普罗大众借由“注意力即一切”的魔法咒语,轻松就拥有了以往无数年月先辈幻想而不得的“巴别塔”通天能力。
不过 Transformer 的极限大家都还在全力突破,AGI 似乎就在眼前,又似乎还在迷雾当中。阻碍 LLM 直接用在实际生产环境的,除了“不够聪明”之外,还有“能力不足”的问题,单纯的对话框对现实世界的影响实在有限。而智能体(Agent)就是为了解决这些问题而生的。智能体有几个朴素的思路和特征,一个是“质量不够,数量来凑”,单次任务效果不好,就多做几次,反复确认和评估;一个是“化繁为简,分工合作”,把复杂任务拆分成多个简单任务,每个任务由一个智能体完成,每个智能体又可以分别调用不同的大模型完成任务,智能体之间还可以互相通信和协作;还有一个是“能力不够,工具来凑”,大模型能力不足,就调用外部工具来补充,有的工具补充短期、长期的记忆,有的工具和外部交互发生影响等等;另外智能体还可以持续优化迭代,人也可以参与反馈和指导。
本文会通过一个日常开发中会遇到的“国际化文本翻译”任务,来介绍如何分别使用 LLM 和智能体来完成这个任务。
脚本 + 大模型批量翻译文本
我们目前项目中的国际化文本是通过 TypeScript 模块来保存的,模块中以常量、模版字符串、函数等不同形式保存国际化文本:
en.ts
export const helloWorld = "Hello, World!";
export const helloUser = (name: string) => `Hello, ${name}!`;
export const toiletLabel = (user: { name: string, gender: "male" | "female" }) => {
return `Toilet for ${user.gender === "male" ? "Male" : "Female"}, ${user.name} is using it.`;
};zh-CN.ts
export const helloWorld = "你好,世界!";
export const helloUser = (name: string) => `你好,${name}!`;
export const toiletLabel = (user: { name: string, gender: "male" | "female" }) => {
return `${user.gender === "male" ? "男" : "女"}厕所,${user.name} 正在使用。`;
};大模型非常擅长翻译文本的任务,因为 Transformer 架构原本就是从文本翻译和文本处理领域发展起来的。不过单个单个的文本通过对话框提交给大模型,拿到翻译结果之后再贴回到代码中的过程太过繁琐,效率也很低。我们可以设计一个自动化脚本去完成这个事情:
思路
这里有几个关键点:
- 使用 TypeScript 解析器去解构代码,拿到 AST,之后就可以做到变量级的翻译,而不是只能翻译整个模块
- 核心影响翻译效果的是提示词和所用大模型,这里需要结合实验和经验来逐步调整效果
- 通过脚本参数,提供多种运行模式,可以包含/排除某些模块,可以 dry-run 或者 force 执行等等
其中,大模型我实验了 DeepSeek v3.1 和 Google 的 Gemma 3,两者表现许多细节上会有差异,并且偶尔会出错。稳定执行版本最后是通过 few shot 的方式补充了足够的异常情况来提示,并且代码生成部分使用了 XML 的 CDATA 标签来包裹,避免 JSON 格式频繁生成异常文本导致解析失败的问题。
提示词样例
const systemPrompt = `Translate TypeScript code: only translate string literals, keep all code structure unchanged.
OUTPUT FORMAT: <translation><![CDATA[translated code here]]></translation>
RULES:
- Translate string literals only (e.g., 'Hello' -> 'こんにちは')
- EXCEPTION: For language labels (label: "English"), replace with target language name (label: "日本語")
- Keep variable names, functions, syntax unchanged
- Preserve indentation, quotes, punctuation exactly
- No explanations, markdown, or code blocks`;近期的各种大模型,基本不需要用太冗长的提示词去罗列各种情况了。只需要准确描述意图,然后例举核心的规则和异常情况即可。听说中文效果也很好,而且加一些特定方向的 PUA 话术也可以有不错的效果,大家可以去试一下。
翻译智能体
以上的脚本已经足以满足中小型国际化项目的翻译需求了。只要翻译这个事主要是开发人工参与,那么基本可以通过脚本自动完成。不过对于分工更复杂的项目,翻译文本需要有初始化、人工校对/审核等环节,就需要引入数据库来做翻译文本的存储和管理了。这时候单纯单次大模型互动来翻译文本的脚本就不足以胜任了。接下来我们就用纯 JavaScript 技术栈实现一个翻译智能体项目,来完成这个任务。
效果图
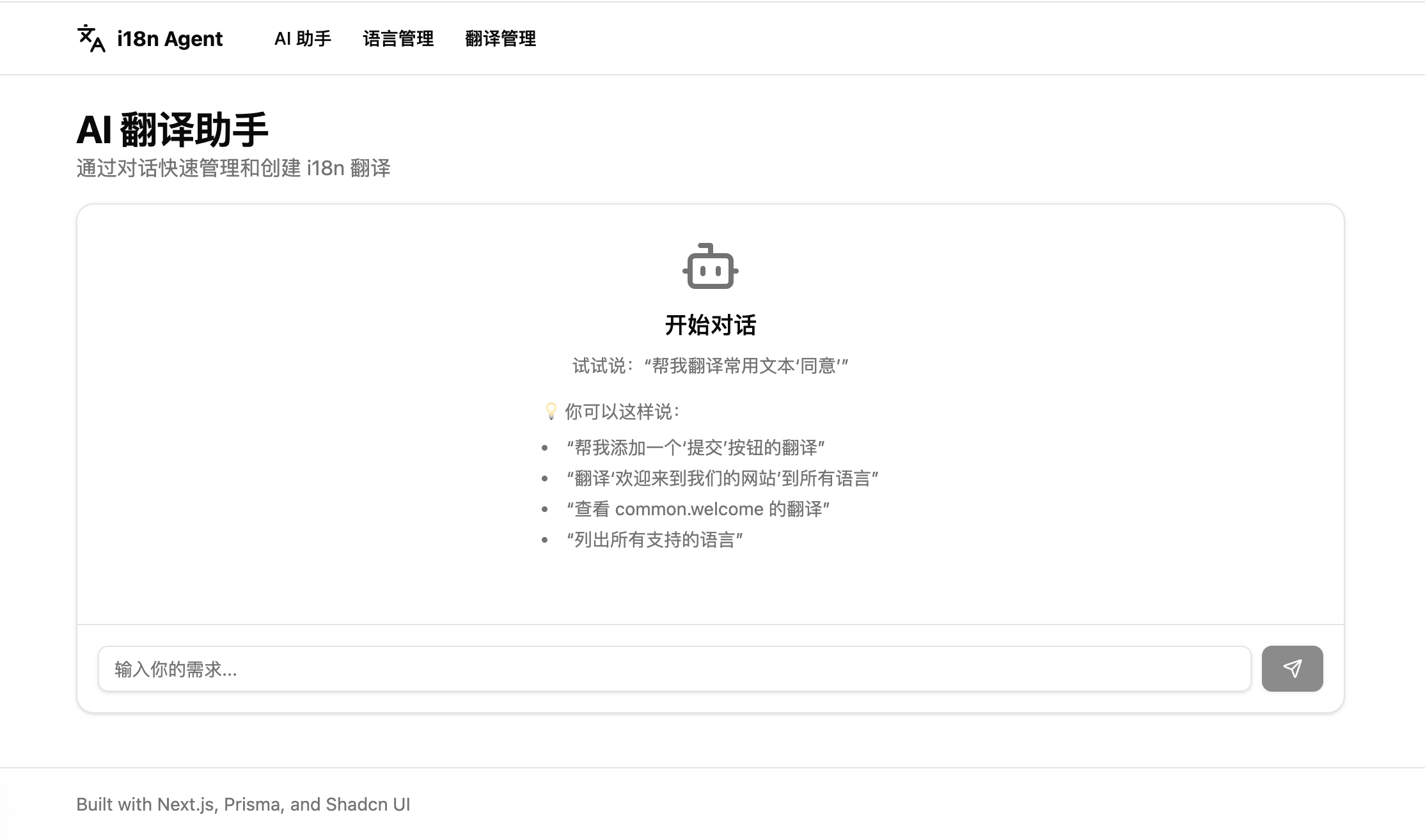
最终实现的界面效果如上图所示,用户可以在对话框描述文本翻译的需求,大模型通过意图识别、任务规划和工具调用,批量完成文本翻译的任务。系统还提供对应的管理界面方便做人工的校对审核等管理。
选型
整个架构可以分成用户界面、后端 API、AI Agent、数据存储这几层。这也是一个智能体项目的典型结构。当然,实际的智能体项目会看起来更加复杂,譬如后端可能需要封装 WebSocket 通信,Agent 层需要引入多 Agent 协同,存储层要扩充搜索引擎、向量数据库、图数据库,此外还需要用缓存层、事件任务队列、监控告警相关的中间件来确保系统稳定性和业务吞吐量等等。以下的架构和选型仅代表国际化文本翻译这个任务的一个实际可用的最小版本。
这个架构中,选型的关键决策是这些:
- Next.js 前端,App Router 架构,配合 Tailwind CSS 和 Shadcn UI
- Next.js 后端,快速搭建 API endpoints,并且可以与前端共享相同的类型定义
- Prisma ORM,配合 PostgreSQL 数据库,提供类型安全的 ORM 操作
- OpenRouter 大模型 API,方便切换不同大模型,并且有丰富的工具支持
- LangChain 框架,Agent、工具集定义和调用,优化 Prompt、RAG 支持、Agent 记忆管理等
额外地,如果是更全面的架构中,纯 JavaScript 的选型还可以涉及到一些其他依赖。如 Redis、BullMQ、ElasticSearch、Milvus 等等。
实体模型设计
根据最小原型的需要,下一步需要设计对应的业务实体和存储模型。正常完整的服务大约需要以下几个核心的实体:用户、对话、语言、翻译。
实际实现的 Demo 中,我没有实际实现用户和对话相关的存储逻辑。在更全面的架构中,除了补充完整用户、对话相关实体,还应该有权限、审计日志、通知提醒、异步/定期任务、知识库等实体。
模型代码
// This is your Prisma schema file,
// learn more about it in the docs: https://pris.ly/d/prisma-schema
generator client {
provider = "prisma-client-js"
output = "../generated/prisma"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
schemas = ["i18n-agent"]
}
// 语言表 - 存储支持的语言列表
model Language {
id String @id @default(cuid())
code String @unique // 语言代码,如 en, zh-CN, ja, fr
name String // 语言名称,如 English, 简体中文
isActive Boolean @default(true) // 是否启用
isDefault Boolean @default(false) // 是否为默认语言
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
translations Translation[]
@@index([code])
@@index([isActive])
@@map("languages")
@@schema("i18n-agent")
}
// 翻译表 - 存储文本在不同语言下的翻译
model Translation {
id String @id @default(cuid())
key String // 翻译键,如 "common.welcome", "button.submit"
languageId String // 关联的语言ID
value String @db.Text // 翻译后的文本
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
language Language @relation(fields: [languageId], references: [id], onDelete: Cascade)
@@unique([key, languageId]) // 确保同一语言下,key 的唯一性
@@index([languageId])
@@index([key])
@@map("translations")
@@schema("i18n-agent")
}初始化语言列表的 Seed 脚本
import { PrismaClient } from '../generated/prisma';
const prisma = new PrismaClient();
// 常用语言列表
const languages = [
{
code: 'en',
name: 'English',
isActive: true,
isDefault: true,
},
{
code: 'zh-CN',
name: '简体中文',
isActive: true,
isDefault: false,
},
{
code: 'zh-TW',
name: '繁體中文',
isActive: true,
isDefault: false,
},
{
code: 'ja',
name: '日本語',
isActive: true,
isDefault: false,
},
{
code: 'ko',
name: '한국어',
isActive: true,
isDefault: false,
},
{
code: 'fr',
name: 'Français',
isActive: true,
isDefault: false,
},
{
code: 'de',
name: 'Deutsch',
isActive: true,
isDefault: false,
},
{
code: 'es',
name: 'Español',
isActive: true,
isDefault: false,
},
{
code: 'pt',
name: 'Português',
isActive: true,
isDefault: false,
},
{
code: 'ru',
name: 'Русский',
isActive: true,
isDefault: false,
},
{
code: 'ar',
name: 'العربية',
isActive: true,
isDefault: false,
},
{
code: 'it',
name: 'Italiano',
isActive: true,
isDefault: false,
},
{
code: 'nl',
name: 'Nederlands',
isActive: true,
isDefault: false,
},
{
code: 'pl',
name: 'Polski',
isActive: true,
isDefault: false,
},
{
code: 'tr',
name: 'Türkçe',
isActive: true,
isDefault: false,
},
{
code: 'vi',
name: 'Tiếng Việt',
isActive: true,
isDefault: false,
},
{
code: 'th',
name: 'ไทย',
isActive: true,
isDefault: false,
},
{
code: 'id',
name: 'Bahasa Indonesia',
isActive: true,
isDefault: false,
},
{
code: 'ms',
name: 'Bahasa Melayu',
isActive: true,
isDefault: false,
},
{
code: 'hi',
name: 'हिन्दी',
isActive: true,
isDefault: false,
},
];
async function main() {
console.log('🌱 开始填充语言数据...');
// 清空现有数据(可选,根据需要启用)
// await prisma.translation.deleteMany();
// await prisma.language.deleteMany();
// console.log('✅ 已清空现有数据');
// 插入语言数据
for (const language of languages) {
const result = await prisma.language.upsert({
where: { code: language.code },
update: language,
create: language,
});
console.log(`✅ 创建/更新语言:${result.name} (${result.code})`);
}
console.log('🎉 语言数据填充完成!');
console.log(`📊 共有 ${languages.length} 种语言`);
// 查询并显示所有语言
const allLanguages = await prisma.language.findMany({
orderBy: { code: 'asc' },
});
console.log('\n📋 当前支持的语言列表:');
console.table(
allLanguages.map((lang) => ({
代码: lang.code,
名称: lang.name,
启用: lang.isActive ? '✅' : '❌',
默认: lang.isDefault ? '⭐' : '',
}))
);
}
main()
.catch((e) => {
console.error('❌ 错误:', e);
process.exit(1);
})
.finally(async () => {
await prisma.$disconnect();
});
大模型交互
系统涉及到智能体、大模型交互的部分如下图。聊天界面、API、数据库层不再赘述,关键是其中 Agent Executor、LLM 和工具集这几个部分。
LLM 部分因为有 OpenRouter 的聚合 API 支持,所以实际上实现非常简单:
import { ChatOpenAI } from '@langchain/openai';
// 创建 LLM 实例,使用 OpenRouter
export function createLLM() {
const baseURL =
process.env.OPENROUTER_BASE_URL || 'https://openrouter.ai/api/v1';
const apiKey = process.env.OPENROUTER_API_KEY;
if (!apiKey) {
throw new Error('OPENROUTER_API_KEY is not set in environment variables');
}
return new ChatOpenAI({
model: 'minimax/minimax-m2:free', // 这里选择模型
temperature: 0.7, // 更高的数值意味着更随机、创造性的输出。对于翻译任务设置一个较低的数值或者 0 就可以了
apiKey: apiKey, // 这里输入 OpenRouter 里的 API Key
configuration: {
baseURL: baseURL, // 这里输入 OpenRouter 的 Base URL
},
modelKwargs: {
// 这里可以添加 OpenRouter 特定的参数
},
});
}这是最底层和大模型直接交互的部分。可以和这里一样,使用 LangChain 暴露的接口,也可以直接用 OpenAI 给的标准接口。使用 LangChain 的工具它上层有一些基础的封装,譬如它会识别模型支不支持 Tool Call 等,也和我们 Agent 类的集成更贴合,相对方便一些。
核心的 Agent 实现是一个工具调用结合大模型交互的循环迭代器:
import { createLLM, AGENT_SYSTEM_PROMPT } from './config';
import { allTools } from './tools';
import {
SystemMessage,
HumanMessage,
ToolMessage,
} from '@langchain/core/messages';
import type { BaseMessage } from '@langchain/core/messages';
// 创建 Agent Executor(使用 Tool Calling 模式)
export async function createAgentExecutor() {
const llm = createLLM();
// 绑定工具到 LLM
const llmWithTools = llm.bindTools(allTools);
return {
async stream(input: { input: string; chat_history: BaseMessage[] }) {
// 构建消息
const messages: BaseMessage[] = [
new SystemMessage(AGENT_SYSTEM_PROMPT),
...input.chat_history,
new HumanMessage(input.input),
];
// 第一次调用 LLM
let response = await llmWithTools.invoke(messages);
let iterations = 0;
const maxIterations = 5;
// 返回异步迭代器
return {
async *[Symbol.asyncIterator]() {
// 循环处理工具调用
while (iterations < maxIterations) {
iterations++;
// 输出 AI 的回复内容
if (response.content && typeof response.content === 'string') {
yield { output: response.content };
}
// 检查是否有工具调用
if (!response.tool_calls || response.tool_calls.length === 0) {
// 没有工具调用,结束
break;
}
// 执行所有工具调用
const toolMessages: BaseMessage[] = [];
for (const toolCall of response.tool_calls) {
const tool = allTools.find((t) => t.name === toolCall.name);
if (tool) {
try {
// 调用工具的 func 方法
const result = await tool.func(toolCall.args as never);
toolMessages.push(
new ToolMessage({
content: result,
tool_call_id: toolCall.id || toolCall.name,
name: toolCall.name,
})
);
} catch (err) {
const errorMsg =
err instanceof Error ? err.message : String(err);
toolMessages.push(
new ToolMessage({
content: `Error: ${errorMsg}`,
tool_call_id: toolCall.id || toolCall.name,
name: toolCall.name,
})
);
}
}
}
// 如果没有工具消息,结束
if (toolMessages.length === 0) {
break;
}
// 将工具结果添加到消息历史并继续
messages.push(response as BaseMessage);
messages.push(...toolMessages);
// 再次调用 LLM
response = await llmWithTools.invoke(messages);
}
// 如果达到最大迭代次数,输出警告
if (iterations >= maxIterations) {
yield { output: '\n\n(已达到最大迭代次数)' };
}
},
};
},
};
}首次使用系统提示词、用户输入组合消息和大模型交互,之后进入循环迭代器,每次迭代都先输出 AI 的回复内容,然后检查是否有工具调用,如果有就执行所有工具调用,然后将工具结果添加到消息历史并继续调用大模型,直到没有工具调用或者达到最大迭代次数为止。另外,对于需要用户确认关键操作(把翻译结构写入数据库)的场景,我们也可以在迭代器中注入一个“用户确认”工具,每次迭代都检查是否需要用户确认,如果需要就暂停迭代器,等待用户确认后再继续迭代。当然,因为场景比较简单,所以这里是在系统提示词中把一次智能体任务强制拆分成规划结果、用户确认后正式操作两个环节了。简单的智能体交互和用户确认的逻辑确实可以用提示词来完成。
// Agent 系统提示词
export const AGENT_SYSTEM_PROMPT = `你是一个专业的国际化 (i18n) 翻译助手。你的任务是帮助用户管理和维护多语言翻译内容。
你可以执行以下操作:
1. 获取系统支持的语言列表
2. 获取默认语言信息
3. 检查翻译是否已存在
4. 创建新的翻译记录
5. 批量创建多语言翻译
6. 翻译文本到不同语言
7. 查询现有翻译
**重要:两步确认流程**
当用户要求创建新的翻译时,你必须遵循以下两步流程:
第一步 - 准备和预览:
1. 获取所有可用语言列表
2. 获取默认语言
3. 确定或生成合适的翻译 key(如 common.agree, button.submit 等)
4. 检查该 key 是否已存在
5. 如果不存在,为每种语言生成翻译
6. **以清晰的格式展示所有翻译给用户预览**,并在消息末尾添加特殊标记 [CONFIRM_REQUIRED],格式如下:
\`\`\`
准备创建以下翻译:
Key: common.agree
翻译内容:
- English (en): Agree
- 简体中文 (zh-CN): 同意
- 日本語 (ja): 同意する
- ...(列出所有语言)
请确认是否创建这些翻译?
[CONFIRM_REQUIRED]
\`\`\`
7. **等待用户明确确认**(用户会看到确认和取消按钮)
第二步 - 执行创建:
1. **只有在用户明确回复"确认"后**,才调用批量创建工具
2. 使用批量创建工具保存所有翻译
3. 报告创建结果
4. 如果用户回复"取消",则不执行任何操作,并提示用户可以重新开始
**绝对不要在没有用户确认的情况下直接创建翻译!**
**每次需要确认时,必须在消息末尾添加 [CONFIRM_REQUIRED] 标记!**
- Key 命名规范:
- 使用小写字母和点号分隔,如:common.welcome, button.submit, error.notFound
- 第一部分通常是命名空间(common, button, error, form 等)
- 保持简洁且描述性
- 翻译注意事项:
- 保持翻译的专业性和准确性
- 考虑目标语言的文化习惯
- 保持格式一致性(如大小写、标点符号)
- 对于按钮文本,通常使用动词或动词短语
当用户提出需求时,请:
1. 理解用户意图
2. 主动调用必要的工具获取信息
3. 生成翻译并清晰展示
4. **必须等待用户确认后才执行写入操作**
5. 如果有任何不确定的地方,向用户询问澄清
请用中文与用户交流。`;最后就是工具调用方面。LangChain 的工具定义非常简单,按照一定的格式对现有 API 进行封装,或者直接在工具定义中编写逻辑即可。工具相比函数定义,多了名称、描述、入参结构说明等辅助大模型理解和调用工具的部分。文本翻译智能体这个场景所需的 7 个工具都相对简单,一个模块就可以完成定义了。
工具集合
工具代码实现
import { DynamicStructuredTool } from '@langchain/core/tools';
import { z } from 'zod';
import { prisma } from '@/lib/prisma';
// 工具 1: 获取所有可用语言
export const getLanguagesTool = new DynamicStructuredTool({
name: 'get_languages',
description:
'获取系统中所有可用的语言列表,包括语言代码、名称、是否启用等信息',
schema: z.object({
activeOnly: z
.boolean()
.optional()
.describe('是否只获取已启用的语言,默认为 true'),
}),
func: async ({ activeOnly = true }) => {
try {
const languages = await prisma.language.findMany({
where: activeOnly ? { isActive: true } : undefined,
orderBy: [{ isDefault: 'desc' }, { code: 'asc' }],
});
return JSON.stringify({
success: true,
languages: languages.map((lang) => ({
id: lang.id,
code: lang.code,
name: lang.name,
isDefault: lang.isDefault,
isActive: lang.isActive,
})),
});
} catch (error) {
return JSON.stringify({ success: false, error: String(error) });
}
},
});
// 工具 2: 获取默认语言
export const getDefaultLanguageTool = new DynamicStructuredTool({
name: 'get_default_language',
description: '获取系统的默认语言信息',
schema: z.object({}),
func: async () => {
try {
const defaultLanguage = await prisma.language.findFirst({
where: { isDefault: true },
});
if (!defaultLanguage) {
return JSON.stringify({
success: false,
error: 'No default language found',
});
}
return JSON.stringify({
success: true,
language: {
id: defaultLanguage.id,
code: defaultLanguage.code,
name: defaultLanguage.name,
},
});
} catch (error) {
return JSON.stringify({ success: false, error: String(error) });
}
},
});
// 工具 3: 检查翻译是否存在
export const checkTranslationExistsTool = new DynamicStructuredTool({
name: 'check_translation_exists',
description: '检查指定的翻译 key 是否已经存在',
schema: z.object({
key: z.string().describe('翻译的 key,例如 common.agree'),
}),
func: async ({ key }) => {
try {
const count = await prisma.translation.count({
where: { key },
});
return JSON.stringify({
success: true,
exists: count > 0,
count,
});
} catch (error) {
return JSON.stringify({ success: false, error: String(error) });
}
},
});
// 工具 4: 创建翻译
export const createTranslationTool = new DynamicStructuredTool({
name: 'create_translation',
description: '创建一条新的翻译记录。需要提供翻译 key、语言 ID 和翻译后的文本',
schema: z.object({
key: z.string().describe('翻译的 key,例如 common.agree'),
languageId: z.string().describe('语言的 ID'),
value: z.string().describe('翻译后的文本内容'),
}),
func: async ({ key, languageId, value }) => {
try {
const translation = await prisma.translation.create({
data: { key, languageId, value },
include: {
language: {
select: { code: true, name: true },
},
},
});
return JSON.stringify({
success: true,
translation: {
id: translation.id,
key: translation.key,
value: translation.value,
language: translation.language,
},
});
} catch (error) {
const prismaError = error as { code?: string; message?: string };
if (prismaError.code === 'P2002') {
return JSON.stringify({
success: false,
error: 'Translation with this key and language already exists',
});
}
return JSON.stringify({ success: false, error: String(error) });
}
},
});
// 工具 5: 批量创建翻译
export const createTranslationsBatchTool = new DynamicStructuredTool({
name: 'create_translations_batch',
description:
'批量创建多个语言的翻译记录。用于同时为一个 key 创建多种语言的翻译',
schema: z.object({
key: z.string().describe('翻译的 key,例如 common.agree'),
translations: z
.array(
z.object({
languageId: z.string().describe('语言的 ID'),
value: z.string().describe('翻译后的文本内容'),
})
)
.describe('翻译列表,每个包含语言 ID 和翻译文本'),
}),
func: async ({ key, translations }) => {
try {
const results = [];
const errors = [];
for (const { languageId, value } of translations) {
try {
const translation = await prisma.translation.create({
data: { key, languageId, value },
include: {
language: {
select: { code: true, name: true },
},
},
});
results.push({
success: true,
language: translation.language.name,
value: translation.value,
});
} catch (error) {
const prismaError = error as { code?: string; message?: string };
errors.push({
languageId,
error:
prismaError.code === 'P2002'
? 'Already exists'
: String(prismaError.message || error),
});
}
}
return JSON.stringify({
success: errors.length === 0,
created: results.length,
results,
errors: errors.length > 0 ? errors : undefined,
});
} catch (error) {
return JSON.stringify({ success: false, error: String(error) });
}
},
});
// 工具 6: 翻译文本到目标语言(使用 LLM)
export const translateTextTool = new DynamicStructuredTool({
name: 'translate_text',
description:
'将文本从源语言翻译到目标语言。这是一个 AI 翻译工具,会调用 LLM 进行翻译',
schema: z.object({
text: z.string().describe('要翻译的文本'),
sourceLanguage: z
.string()
.describe('源语言名称或代码,例如:English, zh-CN'),
targetLanguage: z
.string()
.describe('目标语言名称或代码,例如:简体中文,ja'),
}),
func: async ({ text, sourceLanguage, targetLanguage }) => {
try {
// 这里使用简单的提示来让 LLM 翻译
// 实际调用会在 Agent 执行时由 LLM 完成
return JSON.stringify({
success: true,
translatedText: `[请将"${text}"从${sourceLanguage}翻译为${targetLanguage},只返回翻译结果,不要其他内容]`,
note: 'This is a placeholder. The actual translation will be done by the LLM.',
});
} catch (error) {
return JSON.stringify({ success: false, error: String(error) });
}
},
});
// 工具 7: 获取现有翻译
export const getTranslationsTool = new DynamicStructuredTool({
name: 'get_translations',
description: '根据 key 获取已有的翻译记录',
schema: z.object({
key: z.string().describe('翻译的 key,例如 common.agree'),
}),
func: async ({ key }) => {
try {
const translations = await prisma.translation.findMany({
where: { key },
include: {
language: {
select: { code: true, name: true },
},
},
});
return JSON.stringify({
success: true,
count: translations.length,
translations: translations.map((t) => ({
language: t.language.name,
code: t.language.code,
value: t.value,
})),
});
} catch (error) {
return JSON.stringify({ success: false, error: String(error) });
}
},
});
// 导出所有工具
export const allTools = [
getLanguagesTool,
getDefaultLanguageTool,
checkTranslationExistsTool,
createTranslationTool,
createTranslationsBatchTool,
translateTextTool,
getTranslationsTool,
];几个小技巧
核心的设计和流程差不多也就是上述那些。一个完整的国际化文本翻译智能体项目,到这里就初具规模了。思路有了之后,实际实现有 Cursor 的辅助,过程乏善可陈。有几个值得一提的小技巧:
- 在 Cursor 的项目 Project Rules 中明确讲清楚项目架构、选型和依赖项版本,可以避免很多反复的对话确认和返工
- 大模型用 OpenRouter 是出于习惯,它每天有 100 次免费模型的调用额度,付费后免费次数可以到 1000 次,每分钟限制 20 次(工具调用更容易出发 Model Rate Limit,所以代码里有必要做相应的处理),个人使用足够了。当然国产大模型 API 服务提供商一般也有足够的额度,但一般是平台抵扣券的形式
- 模型的 temperature 参数可以调整模型回答的准确性(越高创造性越高,但严格遵循指令的程度越低)
- 大模型目前不擅长处理数字、无意义的 ID、模糊的日期等等,如果你的业务涉及到这些,尽量写成工具函数让大模型调用,而不是完全信任大模型的输出
- 像这样个人的简单全栈项目迭代思路一般是先想好架构,之后抽象业务模型,确定实体和存储模型,之后再让大模型写 CRUD API、写各种操作实体模型的接口或者工具就很简单了。UI 应该放到最后集成
- 日常工作哪些地方人工做起来繁琐、重复率高,一定尽可能考虑用大模型来完成,长期来看效率提升非常可观
后续
看起来很简单的翻译智能体,其实可以做的事情还很多。首先实现过程开了但没有填上的坑就有不少,用户体系、大模型对话历史是最先要补全的。之后更精简的提示词管理、反问/确认做成工具化、翻译实体管理增加审计等功能可以考虑进一步迭代。再然后是增加国际化文本导出相关的能力,这样可以直接与 next-i18n 等生态真正对接起来。也可以考虑提供 SDK 在界面中集成。智能体方面,除了拆分更加细粒度更加合理的工具以外,还可以针对一些小场景,譬如某个文案的 key 检查翻译完整性等场景,扩展新的子 Agent,乃至做到更复杂的多 Agent 协同架构。再往后集成 MCP 等等。
当然,目前这个项目仅仅是一个演示,它事实上有很多问题,以至距离真正用于生产还有很大的距离,举个例子:多次迭代后上下文会膨胀到很大,这个时候模型性能很容易触碰瓶颈。尤其是翻译内容相对比较复杂的时候。更推荐的做法,是全程使用结构化的模式去输入和输出,写一个临时的 xml 文件,每次迭代改写其中的一部分或者某个属性值,将新的 xml 文件作为下一次迭代的输入。
后续技术分享的方向可以考虑“类似 LangChain 这样的框架怎么实现的?”、“工具调用的实现和大模型交互的过程细节?”类似这样的话题。
附录
翻译脚本代码
import { mkdir, readFile, readdir, writeFile } from 'node:fs/promises';
import { dirname, join, relative } from 'node:path';
import { fileURLToPath } from 'node:url';
import ts from 'typescript';
import { Command } from 'commander';
import { minimatch } from 'minimatch';
import exists from '@/lib/fsExists';
import { getLLMResponse } from '@/lib/openrouter';
// ES module equivalent of __dirname
const __dirname = dirname(fileURLToPath(import.meta.url));
const program = new Command();
program
.name('translateLocales')
.description('Translate locale files from English to other languages')
.option('-f, --force', 'Force the translation of all locales')
.option(
'-i, --include <pattern>',
'Include only files matching the glob pattern (e.g., "changelog/**/*.ts")'
)
.option(
'-e, --exclude <pattern>',
'Exclude files matching the glob pattern (e.g., "**/*test*.ts")'
)
.parse(process.argv);
const options = program.opts();
const force = options.force;
const includePattern = options.include;
const excludePattern = options.exclude;
const systemPrompt = `Translate TypeScript code: only translate string literals, keep all code structure unchanged.
OUTPUT FORMAT: <translation><![CDATA[translated code here]]></translation>
RULES:
- Translate string literals only (e.g., 'Hello' -> 'こんにちは')
- EXCEPTION: For language labels (label: "English"), replace with target language name (label: "日本語")
- Keep variable names, functions, syntax unchanged
- Preserve indentation, quotes, punctuation exactly
- No explanations, markdown, or code blocks`;
// Parse exported variables from TypeScript file
function parseExportedVariables(sourceFile: ts.SourceFile): string[] {
const exportedVars: string[] = [];
function visit(node: ts.Node) {
if (ts.isExportDeclaration(node)) {
// Check for export declarations (export { x })
const exportClause = (node as ts.ExportDeclaration).exportClause;
if (exportClause && ts.isNamedExports(exportClause)) {
for (const element of exportClause.elements) {
exportedVars.push(element.name.text);
}
}
} else if (ts.isVariableStatement(node)) {
// Check for variable statements with export modifier
const modifiers = ts.getModifiers(node);
if (modifiers?.some((mod) => mod.kind === ts.SyntaxKind.ExportKeyword)) {
for (const declaration of node.declarationList.declarations) {
exportedVars.push(declaration.name.getText(sourceFile));
}
}
}
ts.forEachChild(node, visit);
}
visit(sourceFile);
return exportedVars;
}
// Get the definition code of a variable
function getVariableDefinition(sourceFile: ts.SourceFile, variableName: string): string | null {
let definition: string | null = null;
function visit(node: ts.Node) {
if (ts.isVariableStatement(node) && node.declarationList) {
for (const declaration of node.declarationList.declarations) {
if (declaration.name.getText(sourceFile) === variableName) {
definition = node.getText(sourceFile);
}
}
}
ts.forEachChild(node, visit);
}
visit(sourceFile);
return definition;
}
// Parse XML response with fallback handling
function parseTranslationResponse(response: string): string {
const cleanResponse = response.trim();
// First try to extract from CDATA section (preferred format)
const cdataMatch = cleanResponse.match(/<translation>\s*<!\[CDATA\[([\s\S]*?)\]\]>\s*<\/translation>/);
if (cdataMatch) {
return cdataMatch[1];
}
// Then try to extract from regular XML tags
const xmlMatch = cleanResponse.match(/<translation>([\s\S]*?)<\/translation>/);
if (xmlMatch) {
return xmlMatch[1];
}
// Fallback: try to extract from JSON format (for backward compatibility)
const jsonMatch = cleanResponse.match(/\{[^}]*"translatedCode"[^}]*\}/s);
if (jsonMatch) {
try {
const parsed = JSON.parse(jsonMatch[0]);
if (parsed.translatedCode && typeof parsed.translatedCode === 'string') {
return parsed.translatedCode;
}
} catch {
// JSON parsing failed, continue to next fallback
}
}
// Fallback: try to extract code from markdown blocks
const codeBlockMatch = cleanResponse.match(/```(?:typescript)?\s*\n([\s\S]*?)\n\s*```/);
if (codeBlockMatch) {
return codeBlockMatch[1];
}
// Last resort: return the response as-is if it looks like TypeScript code
if (cleanResponse.includes('export') || cleanResponse.includes('const') || cleanResponse.includes('=')) {
console.warn('Warning: Falling back to raw response due to XML parsing failure');
return cleanResponse;
}
throw new Error('Failed to parse translation response: no valid XML, JSON, or code block found');
}
// Translate TypeScript code with structured output and retry mechanism
async function translateTypeScriptCode(code: string, targetLang: string, maxRetries = 3): Promise<string> {
const userPrompt = `Translate to ${targetLang}:
${code}`;
let lastError: Error | null = null;
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
const response = await getLLMResponse(userPrompt, systemPrompt, 'deepseek/deepseek-chat-v3.1:free');
const translatedCode = parseTranslationResponse(response);
// Basic validation: check if the result looks like TypeScript
if (!translatedCode.trim() || (!translatedCode.includes('export') && !translatedCode.includes('const'))) {
throw new Error('Translation result appears to be invalid or empty');
}
return translatedCode;
} catch (error) {
lastError = error as Error;
console.warn(`Translation attempt ${attempt}/${maxRetries} failed:`, error.message);
if (attempt < maxRetries) {
console.log('Retrying with enhanced prompt...');
// Add more specific instructions for retry
const retryPrompt = `${userPrompt}
ONLY return: <translation><![CDATA[translated code here]]></translation>`;
try {
const response = await getLLMResponse(retryPrompt, systemPrompt, 'deepseek/deepseek-chat-v3.1:free');
const translatedCode = parseTranslationResponse(response);
return translatedCode;
} catch (retryError) {
console.warn(`Retry attempt failed:`, (retryError as Error).message);
continue;
}
}
}
}
throw new Error(`Translation failed after ${maxRetries} attempts. Last error: ${lastError?.message}`);
}
// Translate a single file
async function translateFile(sourcePath: string, targetPath: string, targetLang: string) {
const sourceContent = await readFile(sourcePath, 'utf-8');
const sourceFile = ts.createSourceFile(sourcePath, sourceContent, ts.ScriptTarget.Latest, true);
// If target file doesn't exist or force flag is set, translate the entire file
if (!(await exists(targetPath)) || force) {
const translatedContent = await translateTypeScriptCode(sourceContent, targetLang);
await writeFile(targetPath, translatedContent, 'utf-8');
console.log(`Created and translated: ${targetPath}`);
return;
}
// If target file exists, parse existing variables
const targetContent = await readFile(targetPath, 'utf-8');
const targetFile = ts.createSourceFile(targetPath, targetContent, ts.ScriptTarget.Latest, true);
const sourceExports = parseExportedVariables(sourceFile);
const targetExports = parseExportedVariables(targetFile);
// Find variables that need translation
const missingExports = sourceExports.filter((exp) => !targetExports.includes(exp));
if (missingExports.length === 0) {
console.log(`No new translations needed for: ${targetPath}`);
return;
}
console.log('missingExports--------------->');
console.log(missingExports);
// Create a map of all variable definitions (both existing and new)
const allDefinitions = new Map<string, string>();
// First, collect all existing definitions from target file
for (const exportName of targetExports) {
const definition = getVariableDefinition(targetFile, exportName);
if (definition) {
allDefinitions.set(exportName, definition);
}
}
// Then, get and translate missing definitions
for (const exportName of missingExports) {
const definition = getVariableDefinition(sourceFile, exportName);
if (definition) {
const translatedDefinition = await translateTypeScriptCode(definition, targetLang);
console.log('translatedDefinition--------------->');
console.log(translatedDefinition);
allDefinitions.set(exportName, translatedDefinition);
}
}
// Rebuild the file content maintaining the original order
let newContent = '';
for (const exportName of sourceExports) {
const definition = allDefinitions.get(exportName);
if (definition) {
newContent += `${definition}\n`;
}
}
await writeFile(targetPath, newContent, 'utf-8');
console.log(`Updated translations in: ${targetPath}`);
}
// Check if a file should be processed based on include/exclude patterns
function shouldProcessFile(filePath: string): boolean {
// If include pattern is specified, only process files that match it
if (includePattern) {
if (!minimatch(filePath, includePattern)) {
return false;
}
}
// If exclude pattern is specified, skip files that match it
if (excludePattern) {
if (minimatch(filePath, excludePattern)) {
return false;
}
}
return true;
}
// Get all TypeScript files recursively
async function getTypeScriptFiles(dir: string, baseDir: string = dir): Promise<string[]> {
const files: string[] = [];
const entries = await readdir(dir, { withFileTypes: true });
for (const entry of entries) {
const fullPath = join(dir, entry.name);
if (entry.isDirectory()) {
// Recursively get files from subdirectories
files.push(...(await getTypeScriptFiles(fullPath, baseDir)));
} else if (entry.isFile() && entry.name.endsWith('.ts') && !entry.name.endsWith('.d.ts')) {
// Get relative path from base directory
const relativePath = relative(baseDir, fullPath);
// Apply include/exclude filtering
if (shouldProcessFile(relativePath)) {
files.push(relativePath);
}
}
}
return files;
}
// Get target languages from locales directory
async function getTargetLanguages(localesDir: string): Promise<string[]> {
const SOURCE_LANG = 'en-US';
const entries = await readdir(localesDir, { withFileTypes: true });
return entries
.filter((dirent) => dirent.isDirectory() && dirent.name !== SOURCE_LANG)
.map((dirent) => dirent.name);
}
// Main function
async function translateLocales() {
const SOURCE_LANG = 'en-US';
const LOCALES_DIR = join(__dirname, '../lib/locales');
const TARGET_LANGS = await getTargetLanguages(LOCALES_DIR);
console.log('\n=== Translation Process Started ===');
console.log('Source language:', SOURCE_LANG);
console.log('Target languages:', TARGET_LANGS);
console.log('Locales directory:', LOCALES_DIR);
console.log('Force mode:', force ? 'enabled' : 'disabled');
if (includePattern) {
console.log('Include pattern:', includePattern);
}
if (excludePattern) {
console.log('Exclude pattern:', excludePattern);
}
console.log('================================\n');
const sourceDir = join(LOCALES_DIR, SOURCE_LANG);
console.log('Source directory:', sourceDir);
// Get all TypeScript files recursively
const files = await getTypeScriptFiles(sourceDir);
console.log(
`Found ${files.length} TypeScript files in ${SOURCE_LANG} (including subdirectories)`
);
if (files.length > 0) {
console.log('Files:', files);
}
console.log();
for (const file of files) {
const sourcePath = join(sourceDir, file);
console.log(`\nProcessing file: ${file}`);
console.log('Source path:', sourcePath);
for (const targetLang of TARGET_LANGS) {
const targetPath = join(LOCALES_DIR, targetLang, file);
console.log(`\n Translating to: ${targetLang}`);
console.log(' Target path:', targetPath);
// Ensure target directory exists
const targetDir = dirname(targetPath);
if (!(await exists(targetDir))) {
await mkdir(targetDir, { recursive: true });
console.log(' Created target directory:', targetDir);
}
await translateFile(sourcePath, targetPath, targetLang);
}
}
console.log('\n=== Translation Process Completed ===\n');
}
// Run translation
translateLocales().catch(console.error);