前言:搜索引擎历史
搜索引擎,在互联网发展的历史上是不容忽视,甚至是至关重要的。有个经典的站点 Search Engine History 这里有详细的、1945 年至 2016 年左右搜索引擎发展的记录,从中我们可以窥探互联网及搜索引擎的初心、意义和发展沿革。
早期技术
1945 年“As We May Think”
这句话由 Vannevar Bush 于 1945 年发表。他敦促科学家使用 hypertext 和存储扩展的概念和技术,建立全人类的知识体系。并且提出让构想中的这个体系,也就是后来的“互联网”,作为人类思维的辅助补充,作为“外脑”发挥作用。并且提出了启发搜索引擎技术的 memex:一个无限、快速、可靠、可扩展、相互关联的数据存储和检索系统。
1960 到 1990 年代
Gerard Salton:是现代搜索引擎技术之父。他的团队开发了 SMART 信息检索系统,提出了搜索引擎领域多个重要概念:向量空间模型、IDF(反向文档索引频率)、TF(关键词频率)、关键词权重、相关性反馈机制等。他的书《索引理论》很好地阐述了相关理念。
Ted Nelson 1963 年:创建了 Xanadu 项目,并创造了“hypertext(超文本)”这个词。WWW 和 HTML 的大部分初始灵感来自于 Ted 的工作。
ARPANet(Advanced Research Projects Agency Network),1972 年:这个是最早的互联网。

Archie 1990 年:这是第一个字面意义上的搜索引擎。最初的几百个网站大部分出现在 1993 年附近,但 Archie 在 1990 年就建立了。它的原理是使用脚本去收集数据,然后用正则表达式来检索网页文件名称。其后,在其他大学的计算机小组里相继出现了 Veronica、Jughead 和 Gopher 等 Archie 的替代品。
FTP 是在 WWW 出现之前,人们共享数据的主要方式。在 FTP 里共享和检索数据都需要通过 FTP 客户端,这也承担了“前互联网时代”搜索引擎的工作。
1991 年 Tim Berners-Lee 和 WWW(万维网)
最初的万维网诞生于 Tim Berners-Lee 为 CERN 构建的、基于 hypertext 概念的 Enquire 原型系统。之后他基于类似的想法(hypertext 结合 TCP 和 DNS)创建了 WWW,开发了 httpd Web 服务器。
第一个 WWW 站点是 http://info.cern.ch/ 在 1991 年 8 月 6 日首次上线。这个站点解析了什么是万维网,如何使用浏览器和创建 Web 服务器。这个站点也是第一个门户站点,维护各种网站的列表。
1994 年,Berners-Lee 在 MIT 创立了 W3C。
搜索引擎的工作原理
Bot / Robot / Spider
爬虫机器人有很多名称,搜索引擎语境下常用的是 Spider。Robot 也会出现,譬如在配置“搜索引擎索引规则”时,你需要提供的描述文档就叫“robots.txt”。计算机语境里的 Bot 是更广泛的定义,能与用户交互或者收集数据的任何程序都可以称为 Bot。
搜索引擎就是通过爬虫在网上检索获取信息的。爬虫就是像普通浏览器一样请求页面的程序,除了读取网页内容进行索引以外,爬虫还会记录链接信息。链接在搜索引擎中至关重要:
- 链接可以作为站点信任的代表
- 链接文本有助于描述页面内容
- 链接的共同引用数据能用于对站点或者页面进行聚类分析
- 存储链接还能帮助搜索引擎发现新文档以供抓取
近期大热的 ChatGPT 是另一种计算机语境下的机器人代表,是一种“Chatterbot”。
搜索引擎的构成
搜索引擎主要由 3 个部分组成:首先是爬虫,它会跟踪网络上的链接,请求尚未编入索引或者自从编入索引以来有内容更新的页面。然后就是内容索引(index),也称目录(catalog)。当用户使用搜索引擎搜索时,搜索引擎并不会实时检索网络上的内容,而是在搜索大致代表网络内容的、精简提炼的稍稍过时的内容索引。搜索引擎的第三部分是搜索界面和相关软件。对于每一次用户查询,搜索引擎通常会执行以下大部分或者全部操作:
- 接受用户的 query,检查匹配的高级语法,并检查是否有拼写错误,尝试纠错
- 检查查询是否匹配某些垂直搜索数据库(如新闻或产品搜索),如有则把相关检索结果与自然搜索结果合并返回
- 收集自然搜索结果相关页面列表,这些页面根据页面内容、被使用数据和链接引用数据进行排名(Page Rank)
- 请求相关广告列表并放置在搜索结果附近
现实中的搜索引擎服务架构必然比这里介绍的复杂得多,要了解更多信息可以参阅专业的论著,譬如《信息检索导论》等。除了 IR,还有 NLP、Text Mining 等相关领域的著作。
如果想要亲身体验一下开发一个搜索引擎的过程,可以参考这本入门级开发教程:
WWW Wanderer 等
1993 年 6 月,世界迎来了第一个万维网的搜索引擎 WWW Wanderer。这个搜索引擎的数据库被称为 Wandex。但有相当长一段时间爬虫的索引信息滞后。
1993 年 10 月,ALIWEB 试图挑战 WWW Wanderer 的地位。它优化了爬虫抓取页面元信息的逻辑并且允许站长提交页面描述进行索引。
Robots Exclusion Standard
最先,创建 ALIWEB 的作者 Martijn Kojer 创建了 web robots 站点,树立了搜索引擎是否索引站点内容的标准(后来的 robots.txt),这让站点开发者得以为整个站点或者逐个页面阻止爬虫抓取内容。当然默认情况下爬虫是抓取全部内容的。
2005 年,Google 主导了一场反博客垃圾评论的运动,创建了链接级别的 nofollow 属性,这是更细粒度更全面的爬虫排除标准。
门户网站
Tim Berner-Lee 创立万维网时,他同步创建了 the WWW Virtual Library项目。这是门户类网站的雏形。
这类网站与今天的搜索引擎在信息管理和检索的思路很不一样。门户网站倾向于手动编辑网站分类索引;而搜索引擎则高度自动化。相比而言,普遍意义上的门户网站由于缺乏可扩展性和需要投入必要的人力去创建和定期维护检查索引站点的质量,因此维护成本和实时性都比搜索引擎差很多。而后来发展出的垂直领域的专家门户、临时新闻站点(譬如博客)、社交标签站点等,也进一步取代一般性的门户网站。并且门户网站越发展,搜索引擎对于站点的分析越精准,这也进一步挤压了纯门户类站点的需求和盈利能力。
垂直搜索
早期的搜索引擎
WebCrawler 是 Brian Pinkerton 在 1994 年 4 月发布的,它是第一个索引整个页面内容的爬虫。AOL 收购了它,然后 1997 年 Excite 收购了它。此后的很多服务都是模仿 WebCrawler 的作品,包括 Lycos、Infoseek、OpenText 等。
此后的历史上相继出现 AltaVista、Inktomi、Ask.com、AllTheWeb 等历史上昙花一现或者发展不太顺利的搜索引擎服务。
元搜索(Meta Search)
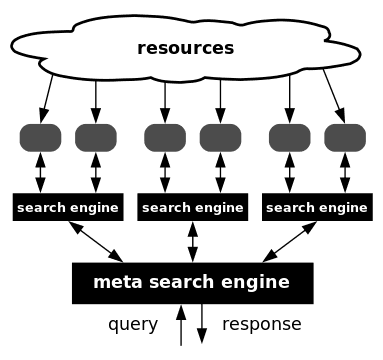
元搜索引擎的做法是从多个其他搜索引擎中提取搜索结果,并整合和重新排名。当不同搜索引擎都不太完善,并且每个搜索引擎也都在某个领域比较擅长时,这样的元搜索引擎是很有用的。但随着搜索引擎技术的改进,其需求也就逐步减少了。
比较早的例子是 Hotbot,另外比较知名的是 DuckDuckGo 等。
垂直搜索(Vertical Search)
垂直领域的搜索服务正不断争夺核心算法搜索引擎之外的垂直领域的内容和市场份额。譬如雅虎的问答服务,以及我们现在多见的知乎、各类编程问题问答网站等。基于不同媒介的搜索服务也逐步形成自闭环,譬如现今比较热门的长视频、短视频搜索等。图书检索、学术信息检索、新闻检索等自不在话下。购物方面的搜索基本都变成大型电商服务自带的功能。
搜索和移动网络
随着移动互联网的发展,移动广告在 2015 年左右开始占据数字广告支出的一半以上。到了移动互联网阶段,互联网搜索引擎的格局基本已经形成寡头效应。有意思的是国内外的情况相差比较大,国内各家互联网巨头都对搜索引擎筑起高墙,搞自己的站内搜索。海外则继续 Google 一家独大,逐渐变为互联网流量的基石。
后事实的网络
互联网让事实传播平民化。而“新闻”媒体的应对则是:全面转向观点迎合与内容娱乐
搜索引擎的兴盛必然导致出版商的衰落。“事实”的获取是如此实时,滞后的出版物,包含在线出版物很难获得用户的注意力。
另外搜索引擎总是倾向于展示权重更高的内容,而人们对内容的分享和链接往往都是带偏见或者特定政治意识形态的。中立的、接近事实的作品或者内容,也许会让大部分人不喜,从而导致其拥趸偏少,也就导致在搜索排行中处于劣势。
搜索引擎营销
搜索引擎的主要商业化手段包括:定向搜索优化、付费搜索广告和付费索引等。
付费索引(竞价排名)
这个太常见,大家都深刻理解了。尤其在某度给世人展示了这项技术如何极端作恶之后。有趣的是,曾经这个方式作为主要有盈利手段的 Google 的企业行为准则之一是“Don't be evil”。
按点击量付费(Pay Per Click)
这个是目前互联网巨头,包括搜索引擎厂商广告收益的一种最常见方式。Pay Per Click 是从付费方式,如果从成本角度分析在线广告模式,对应的是 CPC,也就是 Cost Per Click。其他模式还包括 CPM / CPT / CPA / CPS 等,分别对应千次广告、广告时长、广告用户行为、广告带来的实际销售等。
SEO
SEO,搜索引擎优化,就是针对性地提升某个站点在搜索引擎索引结果中的排名的技术。
早期 SEO 很简单,认真地处理好 TDK、各类 Meta 信息,把站点可用性提升就可以获得足够的流量了。让 Google 在搜索引擎大战中胜出的关键技术 PageRank 也带来进一步的 SEO 思路:我们可以付费购买权重高的站点中的链接,从而让用户更容易搜索到我们想要推广的链接。
但随着搜索引擎索引和排名的算法越来越黑盒化,我们现在做 SEO 已经很难准确预测特定动作会带来什么样的收益。这一点国内外比较一致的现状和趋势就是,搜索引擎厂商在让 SEM 比 SEO 更优先(拥抱氪金大佬)。
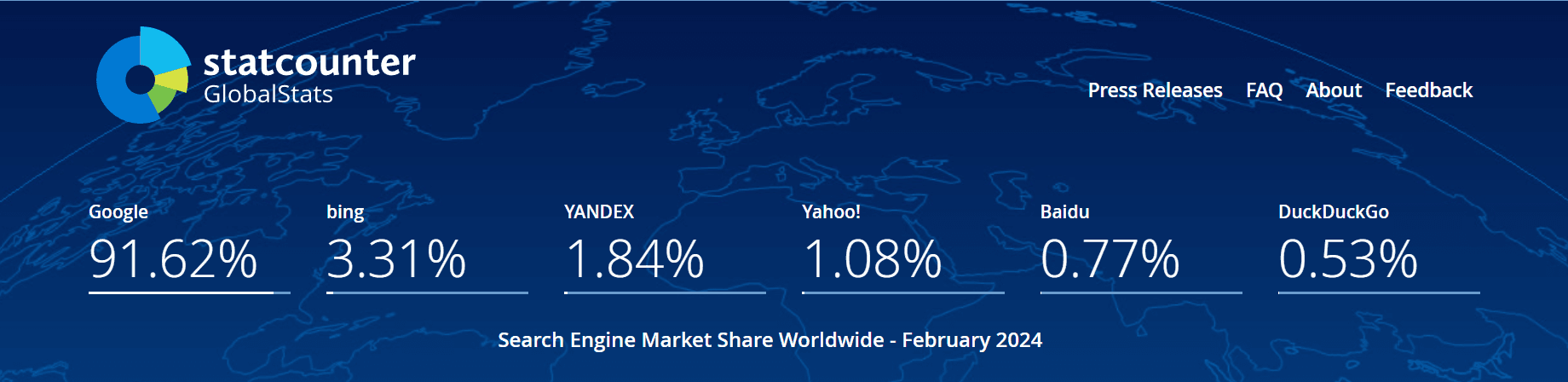
主流厂商
其他
搜索技术会议
- EREC
- ACM SIGIR
- Search Engine Meeting
- AirWeb
索引和扩展阅读
原文引用的大部分资源链接等,经年累月,已不可考。但可以到 Archive.org上查看备份。这里不再累述。
基于 TypeScript 实现一个微型文档搜索引擎
目标
模仿《自制搜索引擎》里的 wiser,对文档合集(类似原书的 Wikipedia 副本)建立一套文档搜索引擎,实现全文检索。用户可以做 ad hoc 查询,不限定搜索范围。
设计
倒排索引
要实现能做全文的搜索引擎,主要有两种方法,第一种是暴力全文匹配,譬如 Uniux-like 系统里的 grep 命令。另一种办法就是建立索引。所谓索引和我们查词典很像,我们想找到某个词出现在词典的哪一页,首先会确定第一个字是什么拼音,找到这个字在的地方;然后按序找余下的字,定位到想找的词。这种方法的好处是,哪怕新词一直在膨胀,我们总是可以在有限的步骤内完成检索,因为拼音是有限的。对于庞大的互联网文本信息而言,某一种语言的总字符集也是渺小的数量级,只要建立好类似的索引,我们也能从浩如烟海的网页里找到自己想要的信息。
那什么叫倒排索引(Inverted Index)呢?它是信息检索系统里最常用的数据结构之一。用简单的检索任务来类比:
> P1
I like search engines
> P2
I search keywords in Google假设我们有两个文档,里面有这些英文单词。我们想要让用户以 ad hoc 的搜索方式,查找某个单词在哪一个文档中。建立倒排索引的过程大致如下:
- 我们先列出每个文档都有哪些关键词。注意英文的话要做大小写、单复数的映射处理
| I | like | search | engine | keyword | in | ||
|---|---|---|---|---|---|---|---|
| P1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| P2 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
- 将这个表格倒转过来,确认“关键词都出现在了哪一个文档中”,也就得到了倒排索引
| P1 | P2 | |
|---|---|---|
| engine | 1 | 0 |
| 0 | 1 | |
| I | 1 | 1 |
| in | 0 | 1 |
| keyword | 0 | 1 |
| like | 1 | 0 |
| search | 1 | 1 |
事实上,倒排索引就由两部分组成:词典 + 文档列表。每一个词都会对应一个文档列表,查询一个复杂句子,事实上就是几个词分别对应的文档列表求交集。当然实际应用里的搜索引擎会比这里描述的索引结构会复杂得多,但基础的原理是这样的。
当然,到此时我们还只是粗暴地得到一个“文档级别的倒排索引”。还有一种“单词级别的倒排索引”,这种倒排索引除了记录单词出现在哪个文档,还会记录单词在文档中出现的位置信息。其数据结构会由 演变为。后续要从倒排索引中查找组合词或者短语,都需要用到单词的位置信息。如果查找到的交集文档里,两个相邻词在某个文档中的 offset 也是相邻的,那么就可以判断这个短语匹配了这篇文档。
中文分词
英文的句法让它制作单词短语的索引非常简单,因为每个单词之间都会有空格分割。中文则不适用这种方法。常用的是词素分词法和 N-gram / q-gram 分词法。
词素分词就是把句子分割为不可分割的、含有意义的最小单位。但中文语法实在太过复杂,并且每年都有新词诞生,要精准分割不致遗漏,是很难的。举例:
文档全文搜索引擎
文档 | 全文 | 搜索 | 引擎N-gram 分词则不依赖具体语言特性。它就是单纯把句子穷举分割成由 N 个字符组成的序列而已,每个序列称为一个 N-gram。N 取值一般是 2 或者 3。N=1 时是 uni-gram,N=2 时是 bi-gram,N=3 时是 tri-gram。如果用 bi-gram 分割上述句子,可以得到:
文档全文搜索引擎
文档 | 档全 | 全文 | 文搜 | 搜索 | 索引 | 引擎这样分词出来的结果是没有遗漏的,因为与语言无关的特性,N-gram 被广泛应用在亚洲国家语言的分词中。
从以上区别能看到,如果能基于词素分词,那分割后的索引数量更少,词典和倒排索引的尺寸会更小,性能会更高。但往往因为新词识别等问题,会存在遗漏。
由 N-gram 分词得到的结果不会有遗漏问题,但相比而言产生的词元(token 或者 term)数量更多,词典和倒排索引的尺寸也就更大,性能会有一定问题。并且也会有误判的问题,譬如用户搜索“九华山”,搜索引擎也会返回“华山”的结果。
外存设计和项目实现
纯演示项目,就用 NestJS 搭了个简单的服务,提供 接口用于提交文档进行归档索引;提供 接口用于搜索。N-gram 分词,词典和倒排索引用 SQLite 存储,ORM 使用 Sequelize。用 NestJS 脚手架 + 各种 XXGPTs 可以快速把项目搭建出来。
想当年研究这个技术的时候,几度陷入“遇到术语 - 理解术语 - 遇到算法 - 实现算法”的循环中,沉迷解题带来的满足感不可自拔。现在再做同样的事,对着 ChatGPT 和 claude.ai 的答案一顿抄,代码编译运行一把过......心里只余下无尽的空虚,大家懂的,就是“我之前的努力究竟是为了什么”的空虚。
话说回来,要做到这种精度的 Prompt 生成这种精度的答案,自然你要先对这个项目本身,整体的运作机制有足够的理解才办得到(暂时的)。所以这里没有掐灭大家求知欲、技术探索欲的意思,我的意思是,现在这个时代,对技术和学科领域边界的探索,变得比以前更轻松了,就好像满级氪金 + 开满挂之后回到新手村的感觉一样。对未尽的编程领域的探索欲望,大家尽情去享受空虚吧。
跑题之后我们重新回头看不那么重要的项目细节吧。
Model
// document.model.ts
import { Table, Column, Model, HasMany } from 'sequelize-typescript';
import { NGram } from './ngram.model';
import { InvertedIndex } from './inverted-index.model';
@Table
export class Document extends Model<Document> {
@Column
url: string;
@Column
title: string;
@Column
content: string;
@HasMany(() => NGram)
ngrams: NGram[ ];
@HasMany(() => InvertedIndex)
invertedIndexes: InvertedIndex[ ];
}
// ngram.model.ts
import { Table, Column, Model, ForeignKey, BelongsTo } from 'sequelize-typescript';
import { Document } from './document.model';
@Table
export class NGram extends Model<NGram> {
@Column
gram: string;
@ForeignKey(() => Document)
@Column
documentId: number;
@BelongsTo(() => Document)
document: Document;
}
// inverted-index.model.ts
import { Table, Column, Model, ForeignKey, BelongsTo } from 'sequelize-typescript';
import { Document } from './document.model';
import { NGram } from './ngram.model';
@Table
export class InvertedIndex extends Model<InvertedIndex> {
@ForeignKey(() => NGram)
@Column
ngramId: number;
@BelongsTo(() => NGram)
ngram: NGram;
@ForeignKey(() => Document)
@Column
documentId: number;
@BelongsTo(() => Document)
document: Document;
}Controller
// document.controller.ts
import { Body, Controller, Post, Query } from '@nestjs/common';
import { DocumentService } from './document.service';
@Controller('document')
export class DocumentController {
constructor(private readonly documentService: DocumentService) {}
@Post('index')
async indexDocument(@Body() doc: { url: string; title: string; content: string }) {
await this.documentService.indexDocument(doc);
}
@Post('search')
async search(@Query('query') query: string) {
return this.documentService.search(query);
}
}Service
这里基本就是 tokenizer 和生成字典以及倒排索引的所有逻辑
// document.service.ts
import { Injectable } from '@nestjs/common';
import { InjectModel } from '@nestjs/sequelize';
import { Document } from './document.model';
import { NGram } from './ngram.model';
import { InvertedIndex } from './inverted-index.model';
@Injectable()
export class DocumentService {
constructor(
@InjectModel(Document) private documentModel: typeof Document,
@InjectModel(NGram) private ngramModel: typeof NGram,
@InjectModel(InvertedIndex) private invertedIndexModel: typeof InvertedIndex,
) {}
async indexDocument(doc: { url: string; title: string; content: string }) {
const document = await this.documentModel.create(doc);
const ngrams = this.generateNGrams(doc.content);
await Promise.all(
ngrams.map(async (gram) => {
const ngramInstance = await this.ngramModel.create({ gram, documentId: document.id });
await this.invertedIndexModel.create({ ngramId: ngramInstance.id, documentId: document.id });
}),
);
}
async search(query: string) {
const ngrams = this.generateNGrams(query);
const ngramIds = await this.ngramModel.findAll({
where: { gram: ngrams },
attributes: ['id'],
raw: true,
});
const documentIds = await this.invertedIndexModel.findAll({
where: { ngramId: ngramIds.map((n) => n.id) },
attributes: ['documentId'],
group: ['documentId'],
raw: true,
});
const documents = await this.documentModel.findAll({
where: { id: documentIds.map((d) => d.documentId) },
});
return documents;
}
private generateNGrams(text: string, n = 2): string[ ] {
const ngrams = [ ];
for (let i = 0; i <= text.length - n; i++) {
ngrams.push(text.slice(i, i + n));
}
return ngrams;
}
}Module
import { Module } from '@nestjs/common';
import { SequelizeModule } from '@nestjs/sequelize';
import { DocumentController } from './document.controller';
import { DocumentService } from './document.service';
import { Document } from './document.model';
import { NGram } from './ngram.model';
import { InvertedIndex } from './inverted-index.model';
@Module({
imports: [SequelizeModule.forFeature([Document, NGram, InvertedIndex])],
controllers: [DocumentController],
providers: [DocumentService],
})
export class DocumentModule {}当然,这个简单版本的实现,其实相比《自制搜索引擎》里面的 wiser 还是有很大差距的。最重要的差距是原作是手撸的检索算法,B+Tree 之类的,而上述的 TS 版本仅仅是“站在 SQLite 的肩膀上”而已。
但这个方向往前走下去,还是有很多好玩的可能性的。譬如字典和汉字拼音序列结合起来,就能做到边输入拼音边出搜索结果了;譬如这么轻量的方案,不做成 NestJS 服务也可以,直接把索引库加载到前端,也能玩全站搜索;譬如貌似我们可以针对特定文本集合,做成本极低的客户端或者网页端的垂直搜索了。对对对,说的就是 Dash,Dash 的客户端就是自建倒排索引用 SQLite 搜索文档的产品。不知道 XXGPT 如此流行的现在,Dash 的作者还能不能悠闲地一年只工作两三个月 😉
搜索引擎 vs 大语言模型(LLM)TODO
结合现在的 AIGC 发展热点,其实更有想象力的方案是定制 LLM,针对提供的文档源做定向定制的 Chatterbot。想象一下未来所有的站点,都可以有一个针对当前站点内容的自然语言问答机器人,其实到那时我们就不需要网站这种繁杂的树状信息架构的东西了,一个聊天框和对话框足够了。所以这也是为什么我之前和大家说,Discord / Telegram 的机器人,其实是次世代的、一定程度代表未来的前端交互模式的原因。
当然,在当下架构化站点、文档还绝对主流的现状下,做一个定制的 LLM 还是有很大作用的。这个留待下次分享。